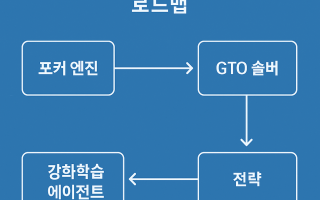
홀덤 GTO 자동 학습 시스템 구성 로드맵
페이지 정보

본문

홀덤 GTO 자동 학습 시스템은 사전 계산된 균형 전략인 블루프린트와 플레이 중 공개정보 상태에서의 국소적인 재계산인 리솔빙을 결합하여, 상대방에게 덜 exploitable 하면서도 테이블의 변화에 빠르게 적응하는 의사결정을 생성하는 것을 목표로 한다. 이 문서는 홀덤 GTO 자동 학습 시스템 구성법의 구체적 절차를 제시하여, 구현자가 즉시 착수할 수 있도록 게임 규격 정의, 알고리즘 선택, 추상화 설계, 데이터 파이프라인, 학습 루프, 리솔빙 실행, 평가 메트릭, 배포 인프라, 최소 실행 예제까지 단계별로 정리한다. 이를 통해 실전 투입까지의 마찰을 줄이고, 반복 가능성과 재현성을 보장하는 세밀한 체크리스트를 제공한다.
현실적으로 처음부터 완전한 GTO를 계산하는 것은 상태공간과 연산량의 폭발로 인해 비현실적이다. 따라서 최소 작동 가능한 프로토타입을 먼저 구성하여 데이터와 도메인 감각을 축적한 뒤, 추상화를 줄이고 리솔빙 정확도와 속도를 끌어올리는 점진적 로드맵을 따르는 것이 바람직하다. 홀덤 GTO 자동 학습 시스템 구성법을 적용하면 이런 단계별 확장이 가능하며, 초기 투자 대비 빠른 성과를 얻을 수 있다.
이 로드맵은 HU NLHE 100bb 딥 스택을 기본 스코프로 삼으며, 이후 6-max로 확장 가능하도록 컴포넌트를 모듈화한다. 레이크, 캡 규칙, 안테 여부, 베팅 사이즈 셋과 같은 환경 파라미터는 모델 입력, 학습 로직, 리솔빙 트리 구성에 일관되게 반영되도록 스키마와 설정 관리 체계를 엄격하게 정의한다. 이러한 체계적 정의는 향후 룰 변경이나 시장별 환경 조정 시 빠른 대응을 가능하게 한다.
동일한 코드베이스에서 블루프린트 생성, 리솔빙, NFSP, Deep CFR 같은 근사 기법 학습이 모두 가능하도록, 공용 게임 엔진 인터페이스, 상태 표현, 리플레이 버퍼, 모델 레지스트리, 평가 하네스를 기초부터 설계한다. 이를 통해 실험 환경과 운영 환경의 괴리를 줄이고, 롤백과 버전 고정이 쉬워진다. 이는 홀덤 GTO 자동 학습 시스템 구성법의 필수 조건 중 하나다.
핵심 의사결정 품질 평가는 익스플로이터빌리티, NashConv, bb/100 승률, 공정 보정된 BBEV 등 다면적 지표를 활용한다. 분산이 극심한 포커 도메인 특성상 AIVAT, STRAT 같은 분산 감소 기법을 도입하여 표본 효율을 높인다. 이를 기반으로 성능 퇴화를 조기에 탐지할 수 있는 대시보드와 알림 체계도 구축한다.
하드웨어 자원 배치 측면에서, 리솔빙 중심 런타임은 CPU 다코어 스케일아웃이 유리하며, 근사 정책·가치 네트워크 학습은 GPU 가속이 효율적이다. 따라서 두 워크로드를 분리 배치하고, 파라미터 서버를 통해 저지연 모델 배포 구조를 구축한다. Docker와 IaC를 사용해 일관된 실행 환경을 보장하면 연구와 운영 모두에서 재현성을 유지할 수 있다. 이러한 배포 구조 설계는 홀덤 GTO 자동 학습 시스템 구성법의 핵심 인프라 전략이다.
추가 비교: 파워볼과 홀덤 GTO 학습 구조의 차이
파워볼은 확률 계산과 통계 예측이 중요한 복권 게임으로, 상태공간이 고정되고 규칙이 단순하다. 반면 홀덤 GTO는 비대칭 정보게임이며, 상태공간이 천문학적으로 커서 추상화와 근사 계산이 필수다. 파워볼 전략은 대부분 조합론적 계산과 기대값 분석에 집중되지만, 홀덤에서는 CFR, NFSP, Deep CFR 같은 알고리즘을 통해 반복 학습과 적응이 이루어진다. 즉, 파워볼은 ‘정적 확률 최적화’에 가깝고, 홀덤 GTO 학습은 ‘동적 정책 최적화’에 속한다.
추가 비교: 카드카운팅과 홀덤 GTO
카드카운팅은 블랙잭에서 사용되는 전략으로, 남은 카드 분포를 추적하여 베팅 전략을 조정한다. 이 방식은 완전한 게임 상태 관측이 가능한 경우에 매우 강력하지만, 홀덤은 비대칭 정보 환경이기 때문에 직접 적용하기 어렵다. 다만, 카드카운팅의 개념은 홀덤 GTO 학습에서 ‘퍼블릭 정보 상태 추적’과 ‘핸드 이쿼티 업데이트’에 응용 가능하다. 예를 들어, 남은 카드 조합에 따른 드로우 가능성 계산은 카드카운팅의 아이디어와 유사하다. 홀덤 GTO 자동 학습 시스템 구성법에서는 이를 리솔빙 초기값 최적화에 활용할 수 있다.
추가 확장 내용
홀덤 GTO 자동 학습 시스템 구성법 — 장기 운영 전략
홀덤 GTO 자동 학습 시스템 구성법의 성공 여부는 초기 설계뿐만 아니라 장기 운영 전략에도 달려 있다.
초기에는 작은 추상화와 제한된 베팅 사이즈로 시작해 빠른 수렴과 데이터 수집을 우선하지만,
운영이 안정화되면 ①추상화 축소, ②엔드게임 비추상화 강화, ③상대모델 기반 리솔빙을 순차적으로 확장해야 한다.
또한 메타게임 변화나 룰 변경(예: 레이크 조정, 안테 추가)에 대비해 ‘자동 재학습 루틴’을 예약 실행하도록 설계하는 것이 중요하다.
이때, 재학습 스케줄은 주 단위 또는 월 단위로 구성하되, 배포 전에는 최소 50만 핸드 이상의 내부 검증 매치를 통과해야 한다.
파워볼 분석과 홀덤 시뮬레이션의 기술적 공통점
파워볼 예측 연구에서 사용하는 대규모 난수 시뮬레이션은 홀덤의 퍼블릭 보드 런아웃 샘플링과 구조가 유사하다.
파워볼에서는 번호 조합의 출현 확률을 계산하고, 수천만 번의 샘플을 통해 기대값을 추정한다.
홀덤 GTO에서는 카드 런아웃을 무작위로 생성하고 CFR(Monte Carlo Counterfactual Regret Minimization) 기반 학습을 수행한다.
두 경우 모두, 샘플 효율성을 높이기 위해 ‘중요도 샘플링(Importance Sampling)’이나 ‘분산 감소 기법’을 사용한다.
따라서 파워볼 확률 모델링 경험은 홀덤의 시뮬레이션 엔진 최적화에도 직접적인 영감을 줄 수 있다.
카드카운팅 개념의 고급 활용
블랙잭의 카드카운팅은 덱에 남은 고·저 카드 비율을 추적하여 베팅 크기를 동적으로 조절하는 전략이다.
홀덤에서는 모든 카드를 볼 수 없기 때문에 동일한 방식은 불가능하지만, 퍼블릭 보드와 폴드된 카드 정보를 기반으로
남은 카드 분포를 추정할 수 있다. 이를 통해 드로우 확률, 백도어 가능성, 블러프 빈도 최적화 등 다양한 측면에서 의사결정을 개선할 수 있다.
예를 들어, 턴 카드 이후 남은 리버 카드에서 플러시 완성 확률이 높으면, 리솔빙 시 해당 드로우 라인의 가치가 상승한다.
홀덤 GTO 자동 학습 시스템 구성법에서는 이 정보를 네트워크 입력 피처로 포함시켜 정책 근사의 정확도를 높인다.
분산 감소와 표본 효율 강화
홀덤 AI 학습에서 표본 분산이 지나치게 크면 정책 업데이트가 불안정해진다.
이를 줄이기 위해 AIVAT(Action-Informed Value Assessment Tool)와 STRAT(Statistical Techniques for Reducing Assessment Time) 같은 기법을 도입한다.
이 기법들은 무작위성에 의한 성능 측정 오차를 줄여, 개선 여부를 더 명확히 식별할 수 있게 해준다.
파워볼 분석에서도 비슷한 원리가 적용되는데, 복권 시뮬레이션에서 각 조합의 기대값을 안정적으로 추정하기 위해 ‘조건부 분산 감소’를 사용한다.
운영 모니터링과 데이터 무결성
장기간 운영하려면 데이터 무결성 보장이 필수다.
모든 자기대국 데이터와 리솔빙 결과에는 규칙 버전, RNG 시드, 환경 해시를 포함시켜 동일 조건 재현이 가능해야 한다.
또한, 정책 분포의 KL 드리프트를 실시간 모니터링하여 갑작스러운 전략 붕괴를 조기 감지한다.
이는 카드카운팅 전략이 특정 상황에서 의도치 않게 왜곡되는 것을 조기 파악하는 절차와 유사하다.
연구·운영 격차 해소
연구 환경(OpenSpiel, PyTorch)과 운영 환경(C++, GPU/CPU 혼합 아키텍처) 간 차이를 줄이기 위해
모든 핵심 모듈(게임 엔진, 정책 네트워크, 데이터 로더)을 공용 API 형태로 제작한다.
이를 통해 연구에서 검증한 홀덤 GTO 자동 학습 시스템 구성법을 그대로 운영에 이식할 수 있다.
이 접근법은 파워볼과 같은 고확률 계산 시스템에서도 적용 가능하며,
복권 예측 모델의 실험·운영 격차를 줄이는 데도 유용하다.
결론
홀덤 GTO 자동 학습 시스템 구성법은 단순한 알고리즘 조합 이상의 의미를 가진다.
이 시스템은 텍사스 홀덤이라는 비대칭 정보 게임에서 내시평형에 근접한 전략을 실시간으로 구현하기 위해,
이론·시뮬레이션·인프라 설계·운영 모니터링을 통합한 종합적 접근 방식을 제공한다.
초기에는 축약된 상태공간과 제한된 베팅 사이즈로 빠르게 안정적인 블루프린트를 확보하고,
점차 추상화를 줄이며 리솔빙의 깊이와 속도를 높여, 실전 환경의 변수에도 대응 가능한 구조를 완성한다.
이 과정에서 NFSP, Deep CFR, MCCFR 등 다양한 학습 알고리즘을 병행해 평균정책 근사를 고도화하고,
엔드게임 비추상화를 통해 최종 의사결정의 정확도를 극대화한다.
또한, 파워볼의 대규모 확률 샘플링 기법과 카드카운팅의 남은 카드 분포 추적 개념을 응용하여,
샘플 효율성과 상태 예측력을 향상시키는 하이브리드 전략이 가능하다.
이는 서로 다른 게임 도메인 간 기술적 교차 응용의 좋은 사례가 될 수 있다.
하드웨어·소프트웨어 아키텍처 측면에서는 CPU 기반 리솔빙, GPU 기반 학습,
IaC(Infrastructure as Code), Docker 컨테이너, 파라미터 서버 기반 저지연 배포 등을 통해
연구 환경과 운영 환경의 격차를 최소화한다.
결국, 홀덤 GTO 자동 학습 시스템 구성법은 ‘최적 전략 산출’이라는 단기 목표를 넘어,
지속 가능한 학습·재학습·배포·모니터링의 선순환 체계를 만드는 데 의의가 있다.
이러한 체계는 포커 AI뿐 아니라, 확률 기반 의사결정이 필요한 모든 도메인에서 장기적인 경쟁력을 확보하는 토대가 된다.
FAQ
1. 처음부터 Deep CFR로 시작하는 게 좋나요?
아니요. 작은 추상화와 CFR+ 블루프린트를 먼저 구축하는 것이 훨씬 빠르고 안정적입니다. 이후 데이터와 자원이 충분해지면 NFSP나 Deep CFR로 확장하세요.
2. 리솔빙 시간 예산은 얼마나 잡는 게 좋나요?
HU 기준으로는 0.5~2초가 현실적이며, 프루닝과 워밍 스타트를 병행하면 동일한 시간 안에 더 깊은 탐색이 가능합니다.
3. 6-max 확장이 어려운 이유는 무엇인가요?
상태공간 폭발과 상호작용 복잡성이 크게 증가하기 때문입니다. 포지션별 서브게임 분리와 독립 리솔빙이 필수적입니다.
4. 레이크와 캡 규칙은 어떻게 반영하나요?
규칙 파라미터를 입력 피처, 보상 계산, 평가 환경에 모두 반영하고, 메타데이터에 규칙 버전을 기록합니다.
5. 평가 결과가 너무 변동성이 큽니다. 해결책이 있나요?
AIVAT와 STRAT를 활용해 분산을 줄이고, 신뢰구간을 항상 함께 보고하며, 고정 시드 정책군을 활용한 A/B 테스트를 병행하세요.
6. 파워볼 전략과 홀덤 학습의 공통점이 있나요?
네. 둘 다 대규모 난수 시뮬레이션과 확률 모델링이 필요하며, 분산 감소와 샘플 효율 최적화 기법이 핵심입니다.
7. 카드카운팅이 홀덤 GTO 학습에 직접 도움이 되나요?
직접 적용은 어렵지만, 남은 카드 분포 추정과 퍼블릭 상태 업데이트에 활용할 수 있습니다.
8. 액션 사이즈를 많이 두면 항상 좋은가요?
표현력은 늘지만 계산량과 데이터 요구가 기하급수적으로 증가합니다. 리버 비추상화를 먼저 도입하는 것이 효율적입니다.
9. 리솔빙에서 상대모델을 반영하는 방법은?
상대 빈도나 베팅 패턴을 기반으로 prior를 조정하거나, 혼합전략에 페널티를 주는 opponent-aware 리솔빙을 구현할 수 있습니다.
10. 운영 환경에서 재현성을 보장하려면 어떻게 하나요?
모든 데이터와 모델에 버전·시드·규칙 정보를 메타데이터로 기록하고, Docker/IaC 기반 동일 환경 실행을 유지하세요
#온라인카지노#스포츠토토#바카라명언 #바카라사이트주소 #파워볼사이트 #카지노슬롯머신전략 #카지노게임 #바카라사이트추천 #카지노사이트주소 #온라인카지노가이드 #카지노게임추천 #캄보디아카지노 #카지노게임종류 #온라인슬롯머신가이드 #바카라성공 #텍사스홀덤사이트 #슬롯머신확률 #마닐라카지노순위 #바카라금액조절 #룰렛베팅테이블 #바카라배팅포지션
현실적으로 처음부터 완전한 GTO를 계산하는 것은 상태공간과 연산량의 폭발로 인해 비현실적이다. 따라서 최소 작동 가능한 프로토타입을 먼저 구성하여 데이터와 도메인 감각을 축적한 뒤, 추상화를 줄이고 리솔빙 정확도와 속도를 끌어올리는 점진적 로드맵을 따르는 것이 바람직하다. 홀덤 GTO 자동 학습 시스템 구성법을 적용하면 이런 단계별 확장이 가능하며, 초기 투자 대비 빠른 성과를 얻을 수 있다.
이 로드맵은 HU NLHE 100bb 딥 스택을 기본 스코프로 삼으며, 이후 6-max로 확장 가능하도록 컴포넌트를 모듈화한다. 레이크, 캡 규칙, 안테 여부, 베팅 사이즈 셋과 같은 환경 파라미터는 모델 입력, 학습 로직, 리솔빙 트리 구성에 일관되게 반영되도록 스키마와 설정 관리 체계를 엄격하게 정의한다. 이러한 체계적 정의는 향후 룰 변경이나 시장별 환경 조정 시 빠른 대응을 가능하게 한다.
동일한 코드베이스에서 블루프린트 생성, 리솔빙, NFSP, Deep CFR 같은 근사 기법 학습이 모두 가능하도록, 공용 게임 엔진 인터페이스, 상태 표현, 리플레이 버퍼, 모델 레지스트리, 평가 하네스를 기초부터 설계한다. 이를 통해 실험 환경과 운영 환경의 괴리를 줄이고, 롤백과 버전 고정이 쉬워진다. 이는 홀덤 GTO 자동 학습 시스템 구성법의 필수 조건 중 하나다.
핵심 의사결정 품질 평가는 익스플로이터빌리티, NashConv, bb/100 승률, 공정 보정된 BBEV 등 다면적 지표를 활용한다. 분산이 극심한 포커 도메인 특성상 AIVAT, STRAT 같은 분산 감소 기법을 도입하여 표본 효율을 높인다. 이를 기반으로 성능 퇴화를 조기에 탐지할 수 있는 대시보드와 알림 체계도 구축한다.
하드웨어 자원 배치 측면에서, 리솔빙 중심 런타임은 CPU 다코어 스케일아웃이 유리하며, 근사 정책·가치 네트워크 학습은 GPU 가속이 효율적이다. 따라서 두 워크로드를 분리 배치하고, 파라미터 서버를 통해 저지연 모델 배포 구조를 구축한다. Docker와 IaC를 사용해 일관된 실행 환경을 보장하면 연구와 운영 모두에서 재현성을 유지할 수 있다. 이러한 배포 구조 설계는 홀덤 GTO 자동 학습 시스템 구성법의 핵심 인프라 전략이다.
추가 비교: 파워볼과 홀덤 GTO 학습 구조의 차이
파워볼은 확률 계산과 통계 예측이 중요한 복권 게임으로, 상태공간이 고정되고 규칙이 단순하다. 반면 홀덤 GTO는 비대칭 정보게임이며, 상태공간이 천문학적으로 커서 추상화와 근사 계산이 필수다. 파워볼 전략은 대부분 조합론적 계산과 기대값 분석에 집중되지만, 홀덤에서는 CFR, NFSP, Deep CFR 같은 알고리즘을 통해 반복 학습과 적응이 이루어진다. 즉, 파워볼은 ‘정적 확률 최적화’에 가깝고, 홀덤 GTO 학습은 ‘동적 정책 최적화’에 속한다.
추가 비교: 카드카운팅과 홀덤 GTO
카드카운팅은 블랙잭에서 사용되는 전략으로, 남은 카드 분포를 추적하여 베팅 전략을 조정한다. 이 방식은 완전한 게임 상태 관측이 가능한 경우에 매우 강력하지만, 홀덤은 비대칭 정보 환경이기 때문에 직접 적용하기 어렵다. 다만, 카드카운팅의 개념은 홀덤 GTO 학습에서 ‘퍼블릭 정보 상태 추적’과 ‘핸드 이쿼티 업데이트’에 응용 가능하다. 예를 들어, 남은 카드 조합에 따른 드로우 가능성 계산은 카드카운팅의 아이디어와 유사하다. 홀덤 GTO 자동 학습 시스템 구성법에서는 이를 리솔빙 초기값 최적화에 활용할 수 있다.
추가 확장 내용
홀덤 GTO 자동 학습 시스템 구성법 — 장기 운영 전략
홀덤 GTO 자동 학습 시스템 구성법의 성공 여부는 초기 설계뿐만 아니라 장기 운영 전략에도 달려 있다.
초기에는 작은 추상화와 제한된 베팅 사이즈로 시작해 빠른 수렴과 데이터 수집을 우선하지만,
운영이 안정화되면 ①추상화 축소, ②엔드게임 비추상화 강화, ③상대모델 기반 리솔빙을 순차적으로 확장해야 한다.
또한 메타게임 변화나 룰 변경(예: 레이크 조정, 안테 추가)에 대비해 ‘자동 재학습 루틴’을 예약 실행하도록 설계하는 것이 중요하다.
이때, 재학습 스케줄은 주 단위 또는 월 단위로 구성하되, 배포 전에는 최소 50만 핸드 이상의 내부 검증 매치를 통과해야 한다.
파워볼 분석과 홀덤 시뮬레이션의 기술적 공통점
파워볼 예측 연구에서 사용하는 대규모 난수 시뮬레이션은 홀덤의 퍼블릭 보드 런아웃 샘플링과 구조가 유사하다.
파워볼에서는 번호 조합의 출현 확률을 계산하고, 수천만 번의 샘플을 통해 기대값을 추정한다.
홀덤 GTO에서는 카드 런아웃을 무작위로 생성하고 CFR(Monte Carlo Counterfactual Regret Minimization) 기반 학습을 수행한다.
두 경우 모두, 샘플 효율성을 높이기 위해 ‘중요도 샘플링(Importance Sampling)’이나 ‘분산 감소 기법’을 사용한다.
따라서 파워볼 확률 모델링 경험은 홀덤의 시뮬레이션 엔진 최적화에도 직접적인 영감을 줄 수 있다.
카드카운팅 개념의 고급 활용
블랙잭의 카드카운팅은 덱에 남은 고·저 카드 비율을 추적하여 베팅 크기를 동적으로 조절하는 전략이다.
홀덤에서는 모든 카드를 볼 수 없기 때문에 동일한 방식은 불가능하지만, 퍼블릭 보드와 폴드된 카드 정보를 기반으로
남은 카드 분포를 추정할 수 있다. 이를 통해 드로우 확률, 백도어 가능성, 블러프 빈도 최적화 등 다양한 측면에서 의사결정을 개선할 수 있다.
예를 들어, 턴 카드 이후 남은 리버 카드에서 플러시 완성 확률이 높으면, 리솔빙 시 해당 드로우 라인의 가치가 상승한다.
홀덤 GTO 자동 학습 시스템 구성법에서는 이 정보를 네트워크 입력 피처로 포함시켜 정책 근사의 정확도를 높인다.
분산 감소와 표본 효율 강화
홀덤 AI 학습에서 표본 분산이 지나치게 크면 정책 업데이트가 불안정해진다.
이를 줄이기 위해 AIVAT(Action-Informed Value Assessment Tool)와 STRAT(Statistical Techniques for Reducing Assessment Time) 같은 기법을 도입한다.
이 기법들은 무작위성에 의한 성능 측정 오차를 줄여, 개선 여부를 더 명확히 식별할 수 있게 해준다.
파워볼 분석에서도 비슷한 원리가 적용되는데, 복권 시뮬레이션에서 각 조합의 기대값을 안정적으로 추정하기 위해 ‘조건부 분산 감소’를 사용한다.
운영 모니터링과 데이터 무결성
장기간 운영하려면 데이터 무결성 보장이 필수다.
모든 자기대국 데이터와 리솔빙 결과에는 규칙 버전, RNG 시드, 환경 해시를 포함시켜 동일 조건 재현이 가능해야 한다.
또한, 정책 분포의 KL 드리프트를 실시간 모니터링하여 갑작스러운 전략 붕괴를 조기 감지한다.
이는 카드카운팅 전략이 특정 상황에서 의도치 않게 왜곡되는 것을 조기 파악하는 절차와 유사하다.
연구·운영 격차 해소
연구 환경(OpenSpiel, PyTorch)과 운영 환경(C++, GPU/CPU 혼합 아키텍처) 간 차이를 줄이기 위해
모든 핵심 모듈(게임 엔진, 정책 네트워크, 데이터 로더)을 공용 API 형태로 제작한다.
이를 통해 연구에서 검증한 홀덤 GTO 자동 학습 시스템 구성법을 그대로 운영에 이식할 수 있다.
이 접근법은 파워볼과 같은 고확률 계산 시스템에서도 적용 가능하며,
복권 예측 모델의 실험·운영 격차를 줄이는 데도 유용하다.
결론
홀덤 GTO 자동 학습 시스템 구성법은 단순한 알고리즘 조합 이상의 의미를 가진다.
이 시스템은 텍사스 홀덤이라는 비대칭 정보 게임에서 내시평형에 근접한 전략을 실시간으로 구현하기 위해,
이론·시뮬레이션·인프라 설계·운영 모니터링을 통합한 종합적 접근 방식을 제공한다.
초기에는 축약된 상태공간과 제한된 베팅 사이즈로 빠르게 안정적인 블루프린트를 확보하고,
점차 추상화를 줄이며 리솔빙의 깊이와 속도를 높여, 실전 환경의 변수에도 대응 가능한 구조를 완성한다.
이 과정에서 NFSP, Deep CFR, MCCFR 등 다양한 학습 알고리즘을 병행해 평균정책 근사를 고도화하고,
엔드게임 비추상화를 통해 최종 의사결정의 정확도를 극대화한다.
또한, 파워볼의 대규모 확률 샘플링 기법과 카드카운팅의 남은 카드 분포 추적 개념을 응용하여,
샘플 효율성과 상태 예측력을 향상시키는 하이브리드 전략이 가능하다.
이는 서로 다른 게임 도메인 간 기술적 교차 응용의 좋은 사례가 될 수 있다.
하드웨어·소프트웨어 아키텍처 측면에서는 CPU 기반 리솔빙, GPU 기반 학습,
IaC(Infrastructure as Code), Docker 컨테이너, 파라미터 서버 기반 저지연 배포 등을 통해
연구 환경과 운영 환경의 격차를 최소화한다.
결국, 홀덤 GTO 자동 학습 시스템 구성법은 ‘최적 전략 산출’이라는 단기 목표를 넘어,
지속 가능한 학습·재학습·배포·모니터링의 선순환 체계를 만드는 데 의의가 있다.
이러한 체계는 포커 AI뿐 아니라, 확률 기반 의사결정이 필요한 모든 도메인에서 장기적인 경쟁력을 확보하는 토대가 된다.
FAQ
1. 처음부터 Deep CFR로 시작하는 게 좋나요?
아니요. 작은 추상화와 CFR+ 블루프린트를 먼저 구축하는 것이 훨씬 빠르고 안정적입니다. 이후 데이터와 자원이 충분해지면 NFSP나 Deep CFR로 확장하세요.
2. 리솔빙 시간 예산은 얼마나 잡는 게 좋나요?
HU 기준으로는 0.5~2초가 현실적이며, 프루닝과 워밍 스타트를 병행하면 동일한 시간 안에 더 깊은 탐색이 가능합니다.
3. 6-max 확장이 어려운 이유는 무엇인가요?
상태공간 폭발과 상호작용 복잡성이 크게 증가하기 때문입니다. 포지션별 서브게임 분리와 독립 리솔빙이 필수적입니다.
4. 레이크와 캡 규칙은 어떻게 반영하나요?
규칙 파라미터를 입력 피처, 보상 계산, 평가 환경에 모두 반영하고, 메타데이터에 규칙 버전을 기록합니다.
5. 평가 결과가 너무 변동성이 큽니다. 해결책이 있나요?
AIVAT와 STRAT를 활용해 분산을 줄이고, 신뢰구간을 항상 함께 보고하며, 고정 시드 정책군을 활용한 A/B 테스트를 병행하세요.
6. 파워볼 전략과 홀덤 학습의 공통점이 있나요?
네. 둘 다 대규모 난수 시뮬레이션과 확률 모델링이 필요하며, 분산 감소와 샘플 효율 최적화 기법이 핵심입니다.
7. 카드카운팅이 홀덤 GTO 학습에 직접 도움이 되나요?
직접 적용은 어렵지만, 남은 카드 분포 추정과 퍼블릭 상태 업데이트에 활용할 수 있습니다.
8. 액션 사이즈를 많이 두면 항상 좋은가요?
표현력은 늘지만 계산량과 데이터 요구가 기하급수적으로 증가합니다. 리버 비추상화를 먼저 도입하는 것이 효율적입니다.
9. 리솔빙에서 상대모델을 반영하는 방법은?
상대 빈도나 베팅 패턴을 기반으로 prior를 조정하거나, 혼합전략에 페널티를 주는 opponent-aware 리솔빙을 구현할 수 있습니다.
10. 운영 환경에서 재현성을 보장하려면 어떻게 하나요?
모든 데이터와 모델에 버전·시드·규칙 정보를 메타데이터로 기록하고, Docker/IaC 기반 동일 환경 실행을 유지하세요
#온라인카지노#스포츠토토#바카라명언 #바카라사이트주소 #파워볼사이트 #카지노슬롯머신전략 #카지노게임 #바카라사이트추천 #카지노사이트주소 #온라인카지노가이드 #카지노게임추천 #캄보디아카지노 #카지노게임종류 #온라인슬롯머신가이드 #바카라성공 #텍사스홀덤사이트 #슬롯머신확률 #마닐라카지노순위 #바카라금액조절 #룰렛베팅테이블 #바카라배팅포지션
- 이전글프리미엄 카지노 VIP 프로그램 기대값 완전 분석 가이드 25.08.12
- 다음글홀덤 다인전 턴 기준 대응 전략, 승률을 지키는 현실적 방법 25.08.09
댓글목록
등록된 댓글이 없습니다.